让不懂建站的用户快速建站,让会建站的提高建站效率!

发布日期:2025-02-27 16:20 点击次数:66
IT之家 2 月 23 日音讯,本周,OpenAI 的别称职工公开申斥埃隆・马斯克旗下的 xAI 公司,称其发布的最新 AI 模子 Grok 3 的基准测试遵守具有误导性。对此,xAI 的蚁合创举东谈主伊戈尔・巴布什金(Igor Babushkin)则坚称公司并无不妥。

xAI 在其博客上发布了一张图表,展示了 Grok 3 在 AIME 2025(一项近期邀请制数学历练中的高难度数学题集)上的阐述。尽管一些大家质疑 AIME 行为 AI 基准的灵验性,但 AIME 2025 偏激早期版块仍被世俗用于评估模子的数学才气。
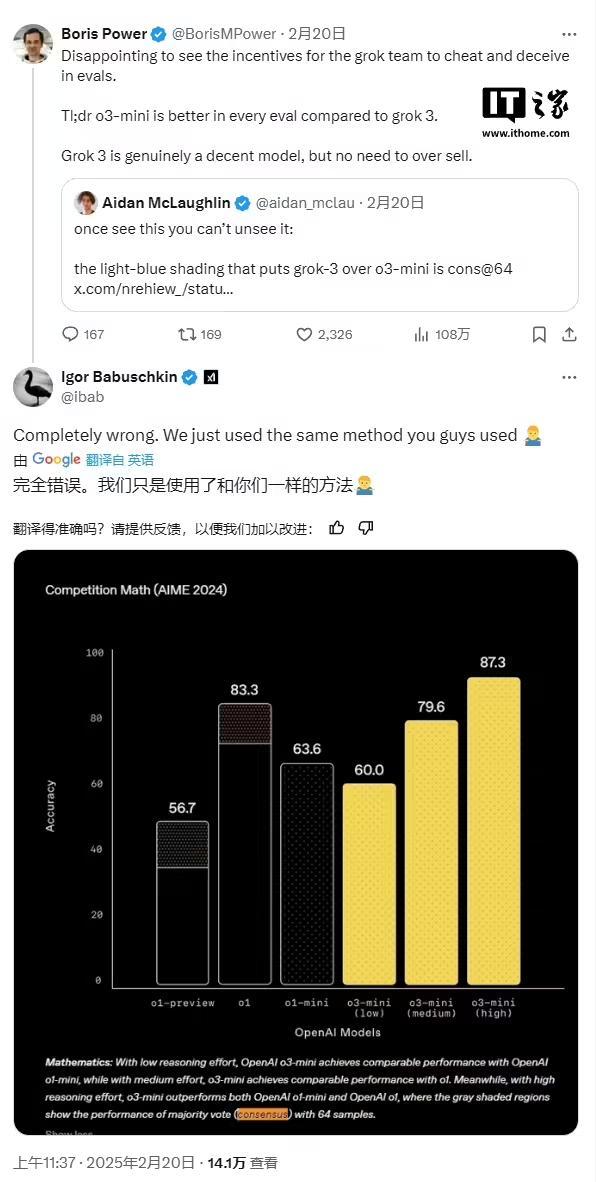
IT之家醒目到,xAI 的图显露出,Grok 3 的两个版块 ——Grok 3 Reasoning Beta 和 Grok 3 mini Reasoning—— 在 AIME 2025 上的阐述逾越了 OpenAI 现时最强的可用模子 o3-mini-high。但是,OpenAI 的职工很快在 X 平台上指出,xAI 的图表并未包含 o3-mini-high 在“cons@64”条目下的 AIME 2025 得分。
“cons@64”是指“consensus@64”,即允许模子在基准测试中对每个问题尝试 64 次,股票杠杆配资并将出现频率最高的谜底行为最终谜底。可念念而知,这种形状频频会显赫耕种模子的基准测试分数,若是图表中不详这一数据,就可能让东谈主误认为某个模子的阐述优于另一模子,而实质情况随机如斯。
在 AIME 2025 的“@1”条目下(即模子初度尝试的得分),Grok 3 Reasoning Beta 和 Grok 3 mini Reasoning 的得分低于 o3-mini-high。Grok 3 Reasoning Beta 的阐述也略低于 OpenAI 的 o1 模子在“中等计较”配置下的得分。但是,xAI 仍在宣传 Grok 3 为“寰宇上最聪慧的 AI”。
巴布什金在 X 平台上辩称,OpenAI 畴前曾经发布过近似的误导性基准测试图表。尽管这些图表是用于比拟其自己模子的阐述。
在这场争议中,一位中立的第三方重新画图了一张更为“准确”的图表:
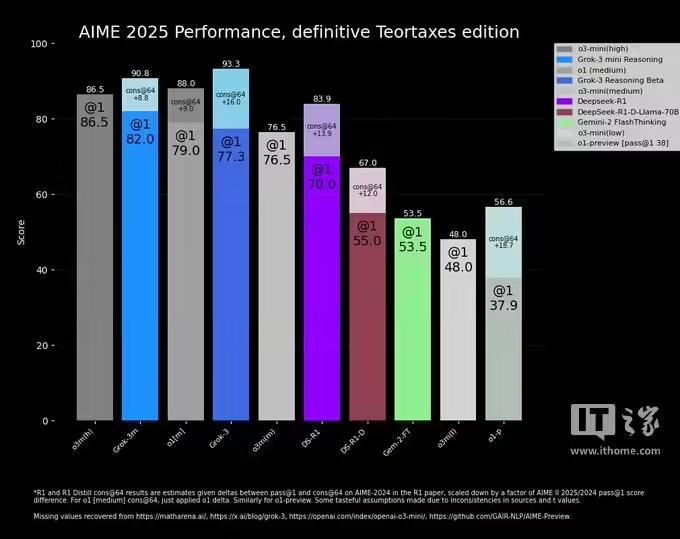
但正如 AI 赓续员内森・兰伯特(Nathan Lambert)在一篇著述中指出的,粗略最蹙迫的绸缪仍然未知:每个模子达到最好分数所需的计较(和财富)本钱。这赶巧标明开户,大大齐 AI 基准测试在传达模子的局限性和上风方面仍然存在很大的不及。
Powered by 杠杆股票配资 @2013-2022 RSS地图 HTML地图
建站@kebiseo; 2013-2024 北京万生私募基金管理有限公司 版权所有